Zero To Hero
The Struggle Continues
Everyone’s seen the Phoronix benchmark numbers by now, and though there’s a lot of confusion over how to calculate the percentage increase between “game does did not run a year ago” and “game runs”, it seems like a couple people out there at Big Triangle are starting to take us seriously.
With that said, even my parents are asking me what the deal is with this one result in particular:
Performance isn’t supposed to go down. Everyone knows this. The version numbers go up and so does the performance as long as it’s not Javascript-based.
Enraged, I sprinted to my computer and searched for tesseract game, which gave me the entirely wrong result, but I eventually did manage to find the right one. I fired up zink-wip, certain that this would end up being some bug I’d already fixed.
Unfortunately, this was not the case.

I vowed not to sleep, rebase, leave my office, or even run another application until this was resolved, so you can imagine how pleased I am to be writing this post after spending way too much time getting to the bottom of everything.
Speculation Interlude
Full disclosure: I didn’t actually check why performance went down. I’m pretty sure it’s just the result of having improved buffer mapping to be better in most cases, which ended up hurting this case.
But Why
…is the performance so bad?
A quick profiling revealed that this was down to a Gallium component called vbuf, used for translating vertex buffers and attributes from the ones specified by the application to ones that drivers can actually support. The component itself is fine, the problem was that, ideally, it’s not something you ever want to be hitting when you want performance.
Consider the usual sequence of drawing a frame:
- generate and upload vertex data
- bind some descriptors
- maybe throw in a query or two if you need some spice
- draw
- repeat until frame is done
This is all great and normal, but what would happen—just hypothetically of course—if instead it looked like this:
- generate and upload vertex data
- stall and read vertex data
- rewrite vertex data in another format and reupload
- bind some descriptors
- maybe throw in a query or two if you need some spice
- draw
- repeat until frame is done
Suddenly the driver is now stalling multiple times per frame on top of doing lots of CPU work!
Incidentally, this is (almost certainly) why performance appeared to have regressed: the vertex buffer is now device-local and can’t be mapped directly, so it has to be copied to a new buffer before it can be read, which is even slower.
Just AMD Problems
DISCLAIMER: We’re going deep into meme territory now, so let’s all dial down the seriousness about a thousand notches before posting about how much I hate AMD or whatever.

Unlike cool hardware, AMD opts to not support features which might be less performant. I assume this is in the hopes that developers will Make The Right Choice and not use those features, but obviously developers are gonna develop, and so it is that Tesseract-The-Game-But-Not-The-One-On-Steam uses 3-component vertex attributes that aren’t supported by AMD hardware, necessitating the use of vbuf to translate them to 4-component attributes that can be safely used.
Decomposition
The vertex buffer format at work here was R8G8B8_SNORM, which is a perfectly cromulent format as long as you hate yourself. A shader would read this as a vec4, which, by the power of buffer robustness, gets translated to vec4(x, y, z, 1.0) because the w component is missing.
The approach I took to solving this was to decompose the vertex attribute into three separate R8_SNORM attributes, as this single-component format is wimpy enough for AMD to handle. Thus, a vertex input state containing three separate attributes including this one would now contain five, as the original R8G8B8_SNORM one is split into three, each reading a single component at an offset to simulate the original attribute.
The tricky part to this is that it requires a vertex shader prolog and variant in order to successfully split the shader’s input in such a way that the read value is the same. It also requires a NIR pass. Let’s check out the NIR pass since this blog has gone for way too long without seeing any real work:
struct decompose_state {
nir_variable **split;
bool needs_w;
};
static bool
decompose_attribs(nir_shader *nir, uint32_t decomposed_attrs, uint32_t decomposed_attrs_without_w)
{
uint32_t bits = 0;
nir_foreach_variable_with_modes(var, nir, nir_var_shader_in)
bits |= BITFIELD_BIT(var->data.driver_location);
bits = ~bits;
u_foreach_bit(location, decomposed_attrs | decomposed_attrs_without_w) {
nir_variable *split[5];
struct decompose_state state;
state.split = split;
nir_variable *var = nir_find_variable_with_driver_location(nir, nir_var_shader_in, location);
assert(var);
split[0] = var;
bits |= BITFIELD_BIT(var->data.driver_location);
const struct glsl_type *new_type = glsl_type_is_scalar(var->type) ? var->type : glsl_get_array_element(var->type);
unsigned num_components = glsl_get_vector_elements(var->type);
state.needs_w = (decomposed_attrs_without_w & BITFIELD_BIT(location)) != 0 && num_components == 4;
for (unsigned i = 0; i < (state.needs_w ? num_components - 1 : num_components); i++) {
split[i+1] = nir_variable_clone(var, nir);
split[i+1]->name = ralloc_asprintf(nir, "%s_split%u", var->name, i);
if (decomposed_attrs_without_w & BITFIELD_BIT(location))
split[i+1]->type = !i && num_components == 4 ? var->type : new_type;
else
split[i+1]->type = new_type;
split[i+1]->data.driver_location = ffs(bits) - 1;
bits &= ~BITFIELD_BIT(split[i+1]->data.driver_location);
nir_shader_add_variable(nir, split[i+1]);
}
var->data.mode = nir_var_shader_temp;
nir_shader_instructions_pass(nir, lower_attrib, nir_metadata_dominance, &state);
}
nir_fixup_deref_modes(nir);
NIR_PASS_V(nir, nir_remove_dead_variables, nir_var_shader_temp, NULL);
optimize_nir(nir);
return true;
}
First, the base of the pass; two masks are provided, one for attributes that are being fully split (i.e., four components) and one for attributes that have fewer than four components and thus need to have a w component added, as in the Tesseract case. Each variable in the mask is split into four, with slightly different behavior for the ones needing a w and the ones that don’t.
The new variables are all given new driver locations matching the ones given to the split attributes for the vertex input pipeline state, and the decompose_state is passed along to the per-instruction part of the pass:
static bool
lower_attrib(nir_builder *b, nir_instr *instr, void *data)
{
struct decompose_state *state = data;
nir_variable **split = state->split;
if (instr->type != nir_instr_type_intrinsic)
return false;
nir_intrinsic_instr *intr = nir_instr_as_intrinsic(instr);
if (intr->intrinsic != nir_intrinsic_load_deref)
return false;
nir_deref_instr *deref = nir_src_as_deref(intr->src[0]);
nir_variable *var = nir_deref_instr_get_variable(deref);
if (var != split[0])
return false;
unsigned num_components = glsl_get_vector_elements(split[0]->type);
b->cursor = nir_after_instr(instr);
nir_ssa_def *loads[4];
for (unsigned i = 0; i < (state->needs_w ? num_components - 1 : num_components); i++)
loads[i] = nir_load_deref(b, nir_build_deref_var(b, split[i+1]));
if (state->needs_w) {
loads[3] = nir_channel(b, loads[0], 3);
loads[0] = nir_channel(b, loads[0], 0);
}
nir_ssa_def *new_load = nir_vec(b, loads, num_components);
nir_ssa_def_rewrite_uses(&intr->dest.ssa, new_load);
nir_instr_remove_v(instr);
return true;
}
The existing variable is passed along with the new variable array. Where the original is loaded, instead the new variables are all loaded in sequence and assembled into a vec matching the length of the original one. For attributes needing a w component, the first new variable is loaded as a vec4 so that the w component can be reused naturally. Then the original load instruction is removed, and with it, the original variable and its brokenness.
Immediate Results
Sort of.
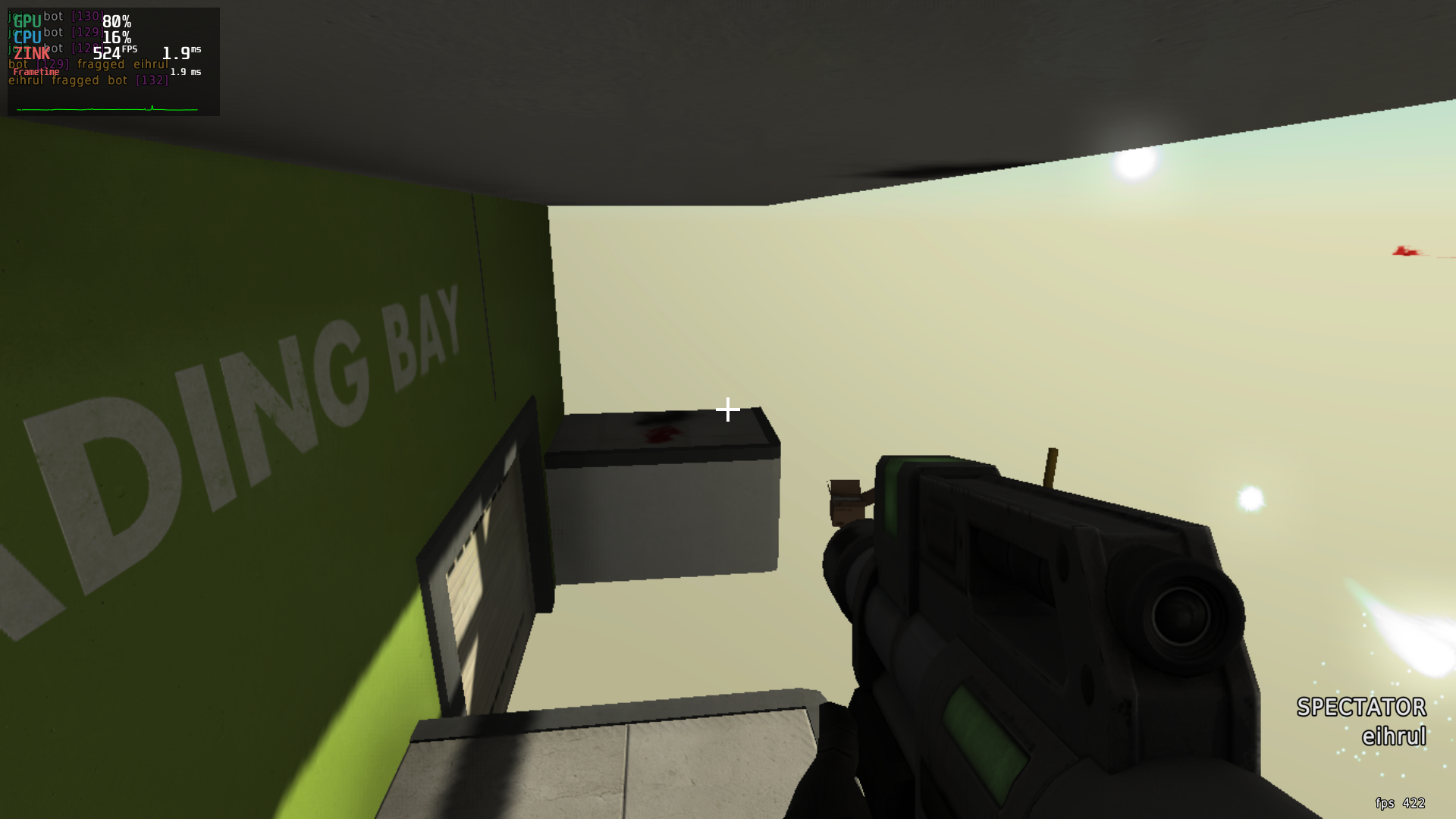
The frames were definitely there, but the graphics…
Occlusion Queries
It turns out there’s almost zero coverage for occlusion queries in Vulkan’s CTS. There’s surprisingly little coverage for most query-related things, in fact, which means it wasn’t too surprising when it turned out that there were RADV query bugs at play. What was surprising was how they manifested, but that was about par for anything that reads garbage memory.
A simple one-liner later (just kidding, this fucken thing took like 4 days to find) and, magically, things were happening:
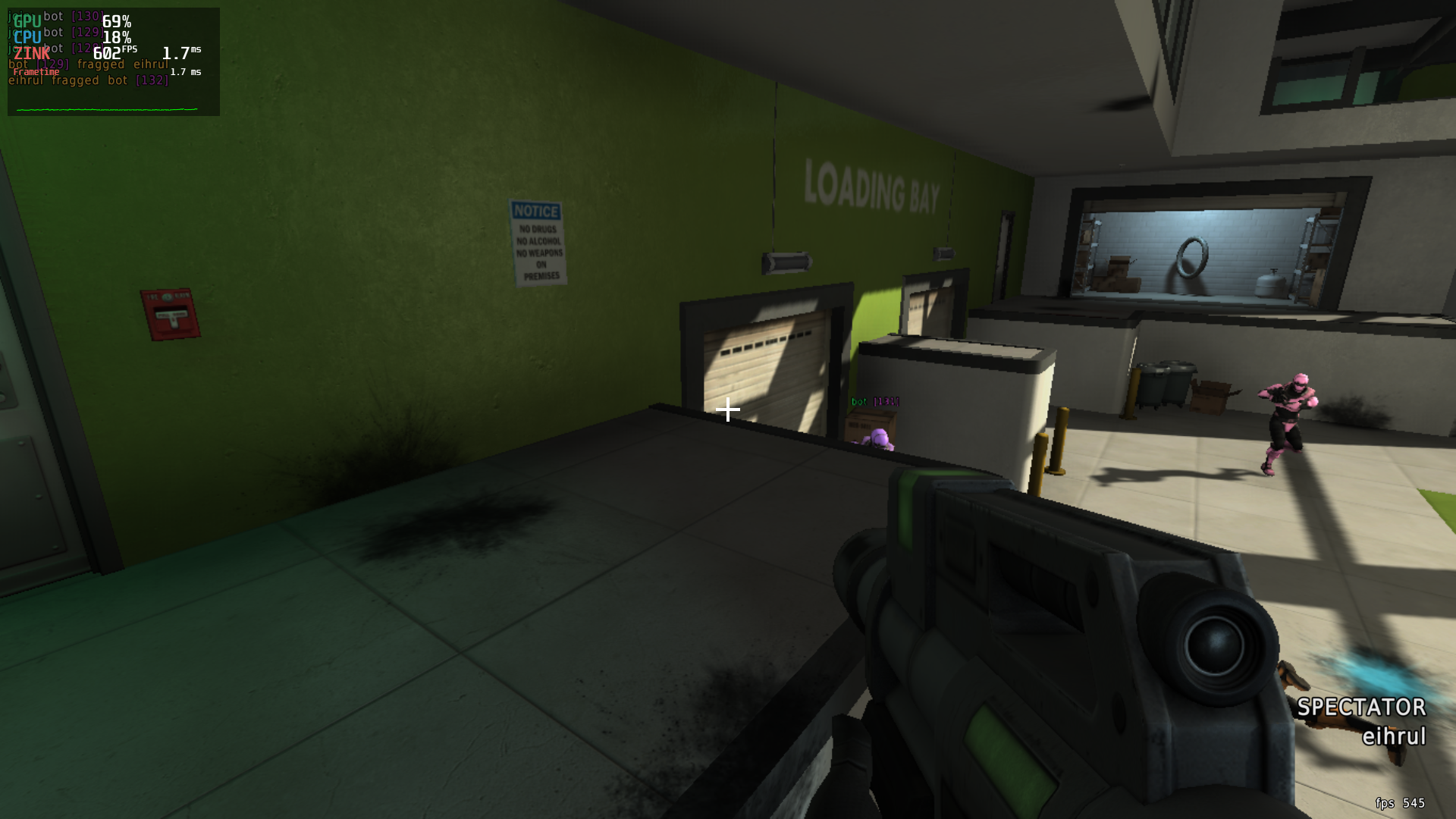
We Did It.
A big thanks to Bas Nieuwenhuizen for consulting along the way even despite being so busy getting a RADV raytracing MR up and, as always, preparing his next blog post.