Cache Harder
Descriptors Once More
It’s just that kind of week.
When I left off in my last post, I’d just implemented a two-tiered cache system for managing descriptor sets which was objectively worse in performance than not doing any caching at all.
Cool.
Next, I did some analysis of actual descriptor usage, and it turned out that the UBO churn was massive, while sampler descriptors were only changed occasionally. This is due to a mechanism in mesa involving a NIR pass which rewrites uniform data passed to the OpenGL context as UBO loads in the shader, compacting the data into a single buffer and allowing it to be more efficiently passed to the GPU. There’s a utility component u_upload_mgr for gallium-based drivers which allocates a large (~100k) buffer and then maps/writes to it at offsets to avoid needing to create a new buffer for this every time the uniform data changes.
The downside of u_upload_mgr, for the current state of zink, is that it means the hashed descriptor states are different for almost every single draw because while the UBO doesn’t actually change, the offset does, and this is necessarily part of the descriptor hash since zink is exclusively using VK_DESCRIPTOR_TYPE_UNIFORM_BUFFER descriptors.
I needed to increase the efficiency of the cache to make it worthwhile, so I decided first to reduce the impact of a changed descriptor state hash during pre-draw updating. This way, even if the UBO descriptor state hash was changing every time, maybe it wouldn’t be so impactful.
Deep Cuts
What this amounted to was to split the giant, all-encompassing descriptor set, which included UBOs, samplers, SSBOs, and shader images, into separate sets such that each type of descriptor would be isolated from changes in the other descriptors between draws.
Thus, I now had four distinct descriptor pools for each program, and I was producing and binding up to four descriptor sets for every draw. I also changed the shader compiler a bit to always bind shader resources to the newly-split sets as well as created some dummy descriptor sets since it’s illegal to bind sets to a command buffer with non-sequential indices, but it was mostly easy work. It seemed like a great plan, or at least one that had a lot of potential for more optimizations based on it. As far as direct performance increases from the split, UBO descriptors would be constantly changing, but maybe…
Well, the patch is pretty big (8 files changed, 766 insertions(+), 450 deletions(-)), but in the end, I was still stuck around 23 fps.
Dynamic UBOs
With this work done, I decided to switch things up a bit and explore using VK_DESCRIPTOR_TYPE_UNIFORM_BUFFER_DYNAMIC descriptors for the mesa-produced UBOs, as this would reduce both the hashing required to calculate the UBO descriptor state (offset no longer needs to be factored in, which is one fewer uint32_t to hash) as well as cache misses due to changing offsets.
Due to potential driver limitations, only these mesa-produced UBOs are dynamic now, otherwise zink might exceed the maxDescriptorSetUniformBuffersDynamic limit, but this was still more than enough.
Boom.
I was now at 27fps, the same as raw bucket allocation.
Hash Performance
I’m not going to talk about hash performance. Mesa uses xxhash internally, and I’m just using the tools that are available.
What I am going to talk about, however, is the amount of hashing and lookups that I was doing.
Let’s take a look at some flamegraphs for the scene that I was showing in my fps screenshots.
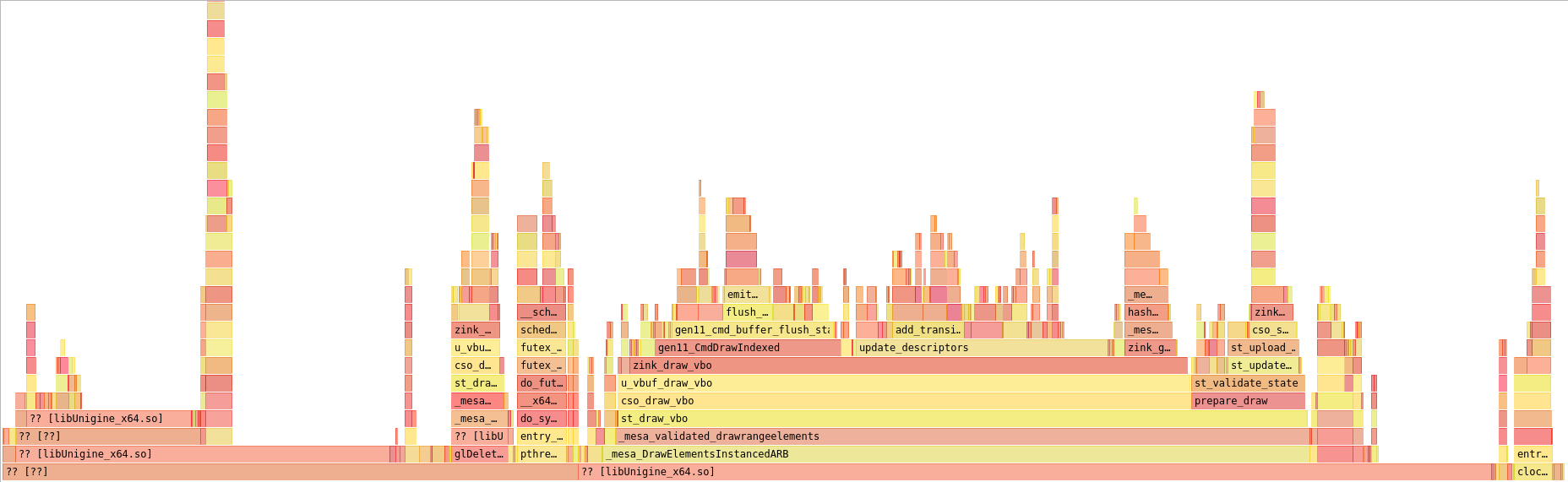
This is, among other things, a view of the juggernaut update_descriptors() function that I linked earlier in the week. At the time of splitting the descriptor sets, it’s over 50% of the driver’s pipe_context::draw_vbo hook, which is decidedly not great.
So I optimized harder.
The leftmost block just above update_descriptors is hashing that’s done to update the descriptor state for cache management. There wasn’t much point in recalculating the descriptor state hash on every draw since there’s plenty of draws where the states remain unchanged. To try and improve this, I moved to a context-based descriptor state tracker, where each pipe_context hook to change active descriptors would invalidate the corresponding descriptor state, and then update_descriptors() could just scan through all the states to see which ones needed to be recalculated.
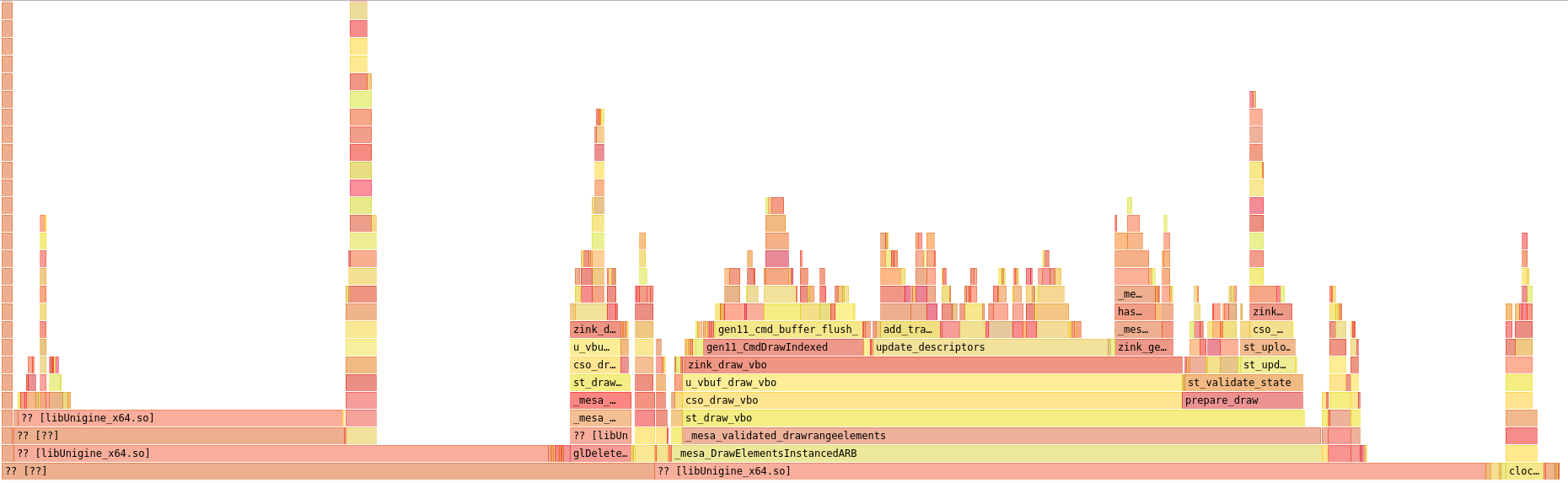
The largest block above update_descriptors() on the right side is the new calculator function for descriptor states. It’s actually a bit more intensive than the old method, but again, this is much more easily optimized than the previous hashing which was scattered throughout a giant 400 line function.
Next, while I was in the area, I added even faster access to reusing descriptor sets. This is as simple as an array of sets on the program struct that can have their hash values directly compared to the current descriptor state that’s needed, avoiding lookups through potentially huge hash tables.
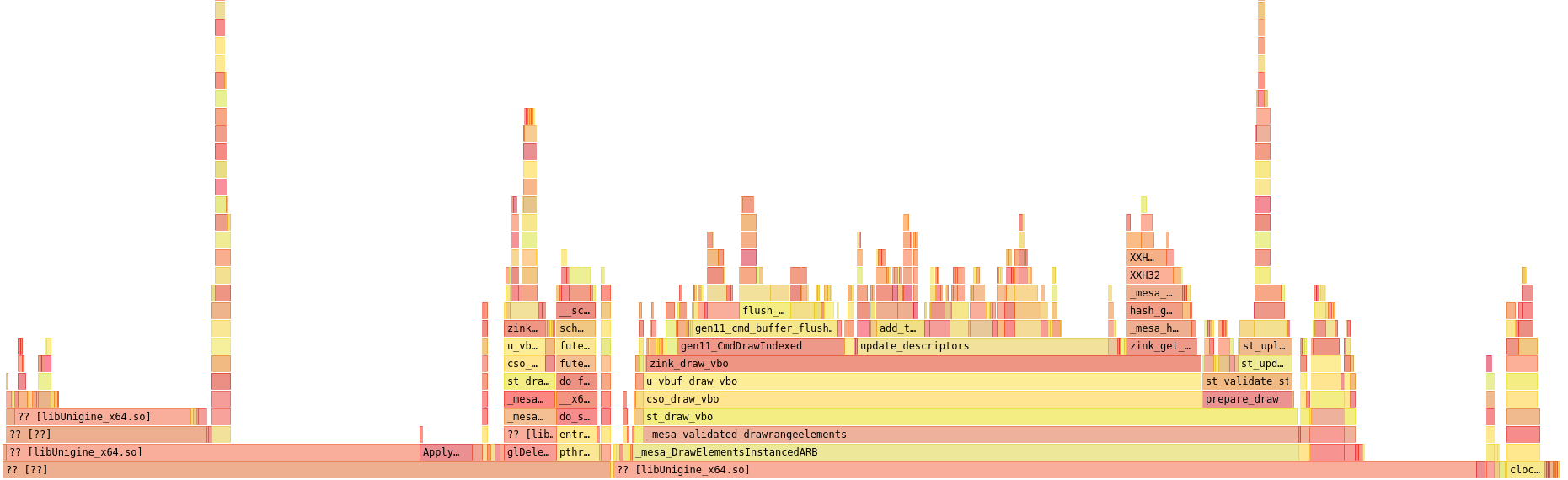
Not much to see here since this isn’t really where any of the performance bottleneck was occurring.
ETOOMUCHHASH
Let’s skip ahead a bit. I finally refactored update_descriptors() into smaller functions to update and bind descriptor sets in a loop prior to applying barriers and issuing the eventual draw command, shaking up the graph quite a bit:
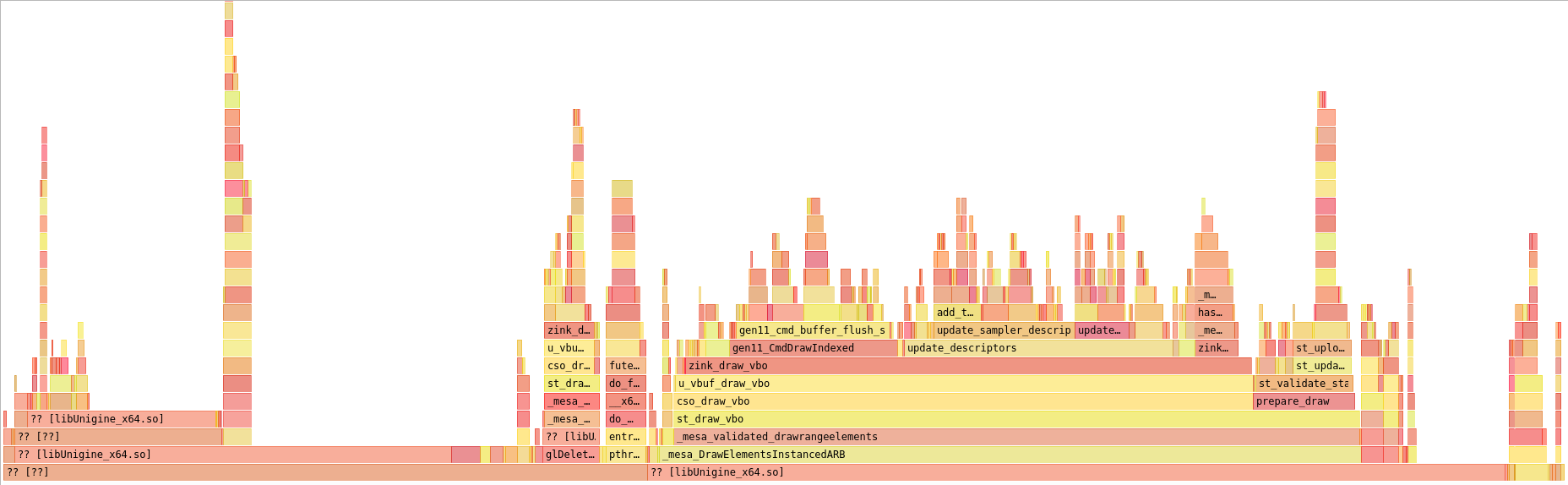
Clearly, updating the sampler descriptors (update_sampler_descriptors()) is taking a huge amount of time. The three large blocks above it are:
- add_transition(), which is a function for accumulating and merging memory barriers for resources using a hash table
- bind_descriptors(), which calls vkUpdateDescriptorSets and vkCmdBindDescriptorSets
- handle_image_descriptor(), which is a helper for setting up sampler/image descriptors
Each of these three had clear ways they could be optimized, and I’m going to speed through that and more in my next post.
But now, a challenge to all the Vulkan experts reading along. In this last section, I’ve briefly covered some refactoring work for descriptor updates.
What is the significant performance regression that I’ve introduced in the course of this refactoring?
It’s possible to determine the solution to my question without reading through any of the linked code, but you have the code available to you nonetheless.
Until next time.