Backish
wew
After a traumatic, tearful goodbye to weird glxgears which took more out of me than expected, I’m back and blogging again.
It’s been…
Well, I guess it’s been a while since my last post, huh.
So what’s happened since then?
Lots? Yeah, definitely lots. It’s May now. And there’s even been a new Mesa release since then.
Quick zink roundup in case you missed any of these:
- shader clocks are in
- sparse buffer support is in
- 16bit ALU support is in
- GPU memory queries are in
Cool.
But What’s Really Been Going On?
The truth is that I’ve been taking some time off from zink in a completely futile attempt to make progress on something else while zink-wip continues to land. Inspired by this ticket describing issues getting CS:GO working, I decided to tackle part of Mesa that I haven’t worked on much and that hasn’t seen much work in a long time:
PBOs.
PBO TIME
Pixel Buffer Objects are used when an application needs to perform a transfer of an image from host memory to the GPU or vice versa. A PBO is said to be downloaded when it is copied from the GPU into a host memory buffer, and it is uploaded when it is copied from a memory buffer into GPU memory. PBO uploads are a common way to load assets from disk (e.g., textures), and PBO downloads are common for…ideally nothing performance related, but RPCS3 uses them in such a way.
Uploading of textures in Mesa can take a number of different codepaths depending on various factors using this priority chain:
- If the format and data type of the pixels is compatible with the format of the texture used for the upload, they can be directly copied by the driver. this is the fastest method
- If the driver supports shader images and the texture format is supported, Gallium will generate a fragment shader which binds the data-to-be-uploaded as a bufferview, the texture as a framebuffer attachment, and then samples to the framebuffer. this is pretty fast
- If the format of the host memory buffer (the data being uploaded) is supported by the driver, Gallium will create a staging texture, memcpy the pixel data into it, and then blit it to the target texture. now we’re slowing down a bit
- Finally, if all else fails, Mesa will just demand the driver maps the target texture so it can dump the pixel data in on the CPU, usually resulting in what looks like a frozen screen because of all the staging textures, flushing, and stalling going on in order to get the pixels where they need to go. this is the bad place
The reason CS:GO takes forever to start with zink is because it performs texture uploads of formats which zink does not support, namely alpha and luminance formats that cannot be emulated in Vulkan, during startup in order to load assets onto the GPU. This hits the CPU copy path 100% of the time, which is actually going to be slower than using something like llvmpipe because GPU-based graphics drivers are not intended to be doing everything on the CPU.
Set PBOs To Ludicrous Speed
I spent a while considering the problem at hand, then decided to start in the place where I could understand what was going on: namely texture downloads. In contrast to uploads, downloads have fewer and simpler codepaths to choose from:
- If the format and data type of the texture matches the requested pixel format, the data is copied directly with memcpy. this is the fastest method
- If the format and data type of the requested pixel format are supported by the driver and the texture format is also compatible with the requested format and type, Gallium creates a staging texture to blit to and then memcpy. this is still pretty okay
- Software fallback. oh no
So to effectively improve this with a new mechanism, all I had to do was meet two criteria:
- Ensure that all formats are supported so that the software fallback is not needed
- Ensure that all format conversions are supported so that the software fallback is not needed
There was also, of course, the additional checklist item of Don’t Be Slower Than The Existing Semi-Fastpath Implementation, but I figured I could get to that later.
The implementation I settled on, after much trial and error, was to set up a SSBO descriptor and then use the source texture as a sampler to texelFetch from in a compute shader. A small, vec4-sized constant buffer is passed to the shader, and then everything is done on the GPU to convert the image to the requested pixel format. The SSBO can then be copied to the output memory buffer, and boom, done.
It took some time to get right, but the results are already quite promising. Here’s some results from pbobench, a tool I’m working on to help measure PBO performance. At present, it populates a 1024x1024 pixel texture using GL_R32F data, then downloads (glGetTextureSubImage) it as fast as possible and measures the number of calls per second, iterating over a number of different formats and types for the download.
Here’s the latest results that I’ve run on IRIS using GL_PACK_ALIGNMENT==4 and GL_PACK_SWAP_BYTES==1 for variety.
32x32
| # | Format | Type | calls/s current | calls/s compute |
|---|---|---|---|---|
| 1 | GL_R32F | GL_FLOAT | 458692 | 20171 |
| 2 | GL_RGBA8 | GL_UNSIGNED_BYTE | 22263 | 20857 |
| 3 | GL_RGB5_A1 | GL_UNSIGNED_BYTE | 22234 | 20211 |
| 4 | GL_RGBA4 | GL_UNSIGNED_BYTE | 22301 | 20247 |
| 5 | GL_SRGB8_ALPHA8 | GL_UNSIGNED_BYTE | 22088 | 20324 |
| 6 | GL_RGBA8_SNORM | GL_BYTE | 22320 | 20315 |
| 7 | GL_RGBA4 | GL_UNSIGNED_SHORT_4_4_4_4 | 22644 | 20094 |
| 8 | GL_RGB5_A1 | GL_UNSIGNED_SHORT_5_5_5_1 | 23189 | 20229 |
| 9 | GL_RGB10_A2 | GL_UNSIGNED_INT_2_10_10_10_REV | 23678 | 19763 |
| 10 | GL_RGB5_A1 | GL_UNSIGNED_INT_2_10_10_10_REV | 23618 | 19914 |
| 11 | GL_RGBA16F | GL_HALF_FLOAT | 208212 | 19306 |
| 12 | GL_RGBA32F | GL_FLOAT | 231616 | 19411 |
| 13 | GL_RGBA16F | GL_FLOAT | 227953 | 18887 |
| 14 | GL_RGB8 | GL_UNSIGNED_BYTE | 22917 | 19691 |
| 15 | GL_RGB565 | GL_UNSIGNED_BYTE | 23000 | 20002 |
| 16 | GL_SRGB8 | GL_UNSIGNED_BYTE | 22852 | 20011 |
| 17 | GL_RGB8_SNORM | GL_BYTE | 26064 | 20006 |
| 18 | GL_RGB565 | GL_UNSIGNED_SHORT_5_6_5 | 24226 | 19813 |
| 19 | GL_R11F_G11F_B10F | GL_UNSIGNED_INT_10F_11F_11F_REV | 140785 | 19755 |
| 20 | GL_R11F_G11F_B10F | GL_HALF_FLOAT | 221776 | 17852 |
| 21 | GL_R11F_G11F_B10F | GL_FLOAT | 193169 | 19660 |
| 22 | GL_RGB9_E5 | GL_UNSIGNED_INT_5_9_9_9_REV | 18616 | 18715 |
| 23 | GL_RGB9_E5 | GL_HALF_FLOAT | 207255 | 18441 |
| 24 | GL_RGB9_E5 | GL_FLOAT | 221998 | 19171 |
| 25 | GL_RGB16F | GL_HALF_FLOAT | 228688 | 18704 |
| 26 | GL_RGB32F | GL_FLOAT | 215211 | 19294 |
| 27 | GL_RGB16F | GL_FLOAT | 233145 | 18858 |
| 28 | GL_RG8 | GL_UNSIGNED_BYTE | 21850 | 18832 |
| 29 | GL_RG8_SNORM | GL_BYTE | 19445 | 18902 |
| 30 | GL_RG16F | GL_HALF_FLOAT | 248270 | 18413 |
| 31 | GL_RG32F | GL_FLOAT | 270652 | 19426 |
| 32 | GL_RG16F | GL_FLOAT | 286874 | 18964 |
| 33 | GL_R8 | GL_UNSIGNED_BYTE | 22093 | 20270 |
| 34 | GL_R8_SNORM | GL_BYTE | 21951 | 20154 |
| 35 | GL_R16F | GL_HALF_FLOAT | 300217 | 19514 |
| 36 | GL_R16F | GL_FLOAT | 454349 | 19784 |
| 37 | GL_RGBA | GL_UNSIGNED_BYTE | 21023 | 19926 |
| 38 | GL_RGBA | GL_UNSIGNED_SHORT_4_4_4_4 | 21408 | 19664 |
| 39 | GL_RGBA | GL_UNSIGNED_SHORT_5_5_5_1 | 22183 | 19090 |
| 40 | GL_RGB | GL_UNSIGNED_BYTE | 21791 | 20054 |
| 41 | GL_RGB | GL_UNSIGNED_SHORT_5_6_5 | 23290 | 19164 |
| 42 | GL_LUMINANCE_ALPHA | GL_UNSIGNED_BYTE | 21032 | 20300 |
| 43 | GL_LUMINANCE | GL_UNSIGNED_BYTE | 21897 | 20565 |
| 44 | GL_ALPHA | GL_UNSIGNED_BYTE | 21941 | 20049 |
The 32x32 size is not very favorable for the new implementation. Drivers are already extremely optimized for small PBO operations, so at best, my work here manages to keep up with the existing codebase for some cases.
Let’s go up a power of two to 64x64.
| # | Format | Type | calls/s current | calls/s compute |
|---|---|---|---|---|
| 45 | GL_R32F | GL_FLOAT | 187911 | 18895 |
| 46 | GL_RGBA8 | GL_UNSIGNED_BYTE | 21094 | 18852 |
| 47 | GL_RGB5_A1 | GL_UNSIGNED_BYTE | 20121 | 18515 |
| 48 | GL_RGBA4 | GL_UNSIGNED_BYTE | 19995 | 18532 |
| 49 | GL_SRGB8_ALPHA8 | GL_UNSIGNED_BYTE | 20829 | 19453 |
| 50 | GL_RGBA8_SNORM | GL_BYTE | 21167 | 18914 |
| 51 | GL_RGBA4 | GL_UNSIGNED_SHORT_4_4_4_4 | 5547 | 19544 |
| 52 | GL_RGB5_A1 | GL_UNSIGNED_SHORT_5_5_5_1 | 5686 | 19762 |
| 53 | GL_RGB10_A2 | GL_UNSIGNED_INT_2_10_10_10_REV | 5934 | 18229 |
| 54 | GL_RGB5_A1 | GL_UNSIGNED_INT_2_10_10_10_REV | 5917 | 18035 |
| 55 | GL_RGBA16F | GL_HALF_FLOAT | 69373 | 17646 |
| 56 | GL_RGBA32F | GL_FLOAT | 66885 | 18507 |
| 57 | GL_RGBA16F | GL_FLOAT | 69091 | 17522 |
| 58 | GL_RGB8 | GL_UNSIGNED_BYTE | 5529 | 18198 |
| 59 | GL_RGB565 | GL_UNSIGNED_BYTE | 5489 | 19197 |
| 60 | GL_SRGB8 | GL_UNSIGNED_BYTE | 5735 | 19455 |
| 61 | GL_RGB8_SNORM | GL_BYTE | 6496 | 19538 |
| 62 | GL_RGB565 | GL_UNSIGNED_SHORT_5_6_5 | 5971 | 19152 |
| 63 | GL_R11F_G11F_B10F | GL_UNSIGNED_INT_10F_11F_11F_REV | 40364 | 19262 |
| 64 | GL_R11F_G11F_B10F | GL_HALF_FLOAT | 76933 | 18650 |
| 65 | GL_R11F_G11F_B10F | GL_FLOAT | 67688 | 18642 |
| 66 | GL_RGB9_E5 | GL_UNSIGNED_INT_5_9_9_9_REV | 4957 | 18894 |
| 67 | GL_RGB9_E5 | GL_HALF_FLOAT | 73775 | 17660 |
| 68 | GL_RGB9_E5 | GL_FLOAT | 69293 | 18703 |
| 69 | GL_RGB16F | GL_HALF_FLOAT | 74131 | 17808 |
| 70 | GL_RGB32F | GL_FLOAT | 67877 | 18735 |
| 71 | GL_RGB16F | GL_FLOAT | 68759 | 17787 |
| 72 | GL_RG8 | GL_UNSIGNED_BYTE | 21194 | 19150 |
| 73 | GL_RG8_SNORM | GL_BYTE | 20644 | 19174 |
| 74 | GL_RG16F | GL_HALF_FLOAT | 90086 | 19010 |
| 75 | GL_RG32F | GL_FLOAT | 88349 | 19285 |
| 76 | GL_RG16F | GL_FLOAT | 89450 | 19041 |
| 77 | GL_R8 | GL_UNSIGNED_BYTE | 21215 | 19813 |
| 78 | GL_R8_SNORM | GL_BYTE | 21280 | 19457 |
| 79 | GL_R16F | GL_HALF_FLOAT | 107419 | 19180 |
| 80 | GL_R16F | GL_FLOAT | 189485 | 19045 |
| 81 | GL_RGBA | GL_UNSIGNED_BYTE | 20784 | 19454 |
| 82 | GL_RGBA | GL_UNSIGNED_SHORT_4_4_4_4 | 5645 | 19375 |
| 83 | GL_RGBA | GL_UNSIGNED_SHORT_5_5_5_1 | 5625 | 19078 |
| 84 | GL_RGB | GL_UNSIGNED_BYTE | 5753 | 19196 |
| 85 | GL_RGB | GL_UNSIGNED_SHORT_5_6_5 | 5917 | 17889 |
| 86 | GL_LUMINANCE_ALPHA | GL_UNSIGNED_BYTE | 5553 | 19014 |
| 87 | GL_LUMINANCE | GL_UNSIGNED_BYTE | 21420 | 18528 |
| 88 | GL_ALPHA | GL_UNSIGNED_BYTE | 21506 | 19944 |
64x64 starts to show some interesting results, cases like GL_SRGB8 where the compute implementation has dominant performance.
| # | Format | Type | calls/s current | calls/s compute |
|---|---|---|---|---|
| 89 | GL_R32F | GL_FLOAT | 55577 | 16096 |
| 90 | GL_RGBA8 | GL_UNSIGNED_BYTE | 17315 | 15264 |
| 91 | GL_RGB5_A1 | GL_UNSIGNED_BYTE | 17735 | 15541 |
| 92 | GL_RGBA4 | GL_UNSIGNED_BYTE | 17191 | 15486 |
| 93 | GL_SRGB8_ALPHA8 | GL_UNSIGNED_BYTE | 17343 | 14831 |
| 94 | GL_RGBA8_SNORM | GL_BYTE | 17362 | 15710 |
| 95 | GL_RGBA4 | GL_UNSIGNED_SHORT_4_4_4_4 | 1367 | 15981 |
| 96 | GL_RGB5_A1 | GL_UNSIGNED_SHORT_5_5_5_1 | 1367 | 16372 |
| 97 | GL_RGB10_A2 | GL_UNSIGNED_INT_2_10_10_10_REV | 1475 | 15181 |
| 98 | GL_RGB5_A1 | GL_UNSIGNED_INT_2_10_10_10_REV | 1482 | 14789 |
| 99 | GL_RGBA16F | GL_HALF_FLOAT | 19254 | 14916 |
| 100 | GL_RGBA32F | GL_FLOAT | 18465 | 13109 |
| 101 | GL_RGBA16F | GL_FLOAT | 18141 | 13075 |
| 102 | GL_RGB8 | GL_UNSIGNED_BYTE | 1439 | 16143 |
| 103 | GL_RGB565 | GL_UNSIGNED_BYTE | 1441 | 16252 |
| 104 | GL_SRGB8 | GL_UNSIGNED_BYTE | 1407 | 16106 |
| 105 | GL_RGB8_SNORM | GL_BYTE | 1583 | 16071 |
| 106 | GL_RGB565 | GL_UNSIGNED_SHORT_5_6_5 | 1520 | 16246 |
| 107 | GL_R11F_G11F_B10F | GL_UNSIGNED_INT_10F_11F_11F_REV | 10888 | 16137 |
| 108 | GL_R11F_G11F_B10F | GL_HALF_FLOAT | 22128 | 14779 |
| 109 | GL_R11F_G11F_B10F | GL_FLOAT | 18807 | 13986 |
| 110 | GL_RGB9_E5 | GL_UNSIGNED_INT_5_9_9_9_REV | 1251 | 15138 |
| 111 | GL_RGB9_E5 | GL_HALF_FLOAT | 22464 | 14482 |
| 112 | GL_RGB9_E5 | GL_FLOAT | 18562 | 14075 |
| 113 | GL_RGB16F | GL_HALF_FLOAT | 22072 | 15038 |
| 114 | GL_RGB32F | GL_FLOAT | 18801 | 14100 |
| 115 | GL_RGB16F | GL_FLOAT | 18774 | 13864 |
| 116 | GL_RG8 | GL_UNSIGNED_BYTE | 18446 | 16890 |
| 117 | GL_RG8_SNORM | GL_BYTE | 18493 | 17353 |
| 118 | GL_RG16F | GL_HALF_FLOAT | 26391 | 15989 |
| 119 | GL_RG32F | GL_FLOAT | 25502 | 15230 |
| 120 | GL_RG16F | GL_FLOAT | 25498 | 15027 |
| 121 | GL_R8 | GL_UNSIGNED_BYTE | 18754 | 17213 |
| 122 | GL_R8_SNORM | GL_BYTE | 16275 | 17254 |
| 123 | GL_R16F | GL_HALF_FLOAT | 31097 | 16525 |
| 124 | GL_R16F | GL_FLOAT | 54923 | 16005 |
| 125 | GL_RGBA | GL_UNSIGNED_BYTE | 17905 | 15956 |
| 126 | GL_RGBA | GL_UNSIGNED_SHORT_4_4_4_4 | 1434 | 16266 |
| 127 | GL_RGBA | GL_UNSIGNED_SHORT_5_5_5_1 | 1462 | 16251 |
| 128 | GL_RGB | GL_UNSIGNED_BYTE | 1465 | 16370 |
| 129 | GL_RGB | GL_UNSIGNED_SHORT_5_6_5 | 1525 | 16550 |
| 130 | GL_LUMINANCE_ALPHA | GL_UNSIGNED_BYTE | 1416 | 15919 |
| 131 | GL_LUMINANCE | GL_UNSIGNED_BYTE | 18876 | 16872 |
| 132 | GL_ALPHA | GL_UNSIGNED_BYTE | 17523 | 16271 |
By the 128x128 texture size, the massive performance lead that the existing glGetTextureSubImage handling had has dwindled to 20-50% for some cases, while the compute shader is now outperforming by a factor of ten or more for other cases.
| # | Format | Type | calls/s current | calls/s compute |
|---|---|---|---|---|
| 133 | GL_R32F | GL_FLOAT | 14768 | 8850 |
| 134 | GL_RGBA8 | GL_UNSIGNED_BYTE | 10980 | 9142 |
| 135 | GL_RGB5_A1 | GL_UNSIGNED_BYTE | 11034 | 9063 |
| 136 | GL_RGBA4 | GL_UNSIGNED_BYTE | 11104 | 9160 |
| 137 | GL_SRGB8_ALPHA8 | GL_UNSIGNED_BYTE | 11196 | 9085 |
| 138 | GL_RGBA8_SNORM | GL_BYTE | 10843 | 9139 |
| 139 | GL_RGBA4 | GL_UNSIGNED_SHORT_4_4_4_4 | 500 | 10001 |
| 140 | GL_RGB5_A1 | GL_UNSIGNED_SHORT_5_5_5_1 | 496 | 9775 |
| 141 | GL_RGB10_A2 | GL_UNSIGNED_INT_2_10_10_10_REV | 484 | 8868 |
| 142 | GL_RGB5_A1 | GL_UNSIGNED_INT_2_10_10_10_REV | 508 | 8994 |
| 143 | GL_RGBA16F | GL_HALF_FLOAT | 5025 | 7952 |
| 144 | GL_RGBA32F | GL_FLOAT | 4731 | 6635 |
| 145 | GL_RGBA16F | GL_FLOAT | 4722 | 6519 |
| 146 | GL_RGB8 | GL_UNSIGNED_BYTE | 497 | 9356 |
| 147 | GL_RGB565 | GL_UNSIGNED_BYTE | 499 | 9181 |
| 148 | GL_SRGB8 | GL_UNSIGNED_BYTE | 479 | 9067 |
| 149 | GL_RGB8_SNORM | GL_BYTE | 784 | 9704 |
| 150 | GL_RGB565 | GL_UNSIGNED_SHORT_5_6_5 | 527 | 9569 |
| 151 | GL_R11F_G11F_B10F | GL_UNSIGNED_INT_10F_11F_11F_REV | 1396 | 8938 |
| 152 | GL_R11F_G11F_B10F | GL_HALF_FLOAT | 5697 | 8283 |
| 153 | GL_R11F_G11F_B10F | GL_FLOAT | 4760 | 6599 |
| 154 | GL_RGB9_E5 | GL_UNSIGNED_INT_5_9_9_9_REV | 444 | 8123 |
| 155 | GL_RGB9_E5 | GL_HALF_FLOAT | 5836 | 8305 |
| 156 | GL_RGB9_E5 | GL_FLOAT | 4782 | 6944 |
| 157 | GL_RGB16F | GL_HALF_FLOAT | 5669 | 8313 |
| 158 | GL_RGB32F | GL_FLOAT | 4759 | 6819 |
| 159 | GL_RGB16F | GL_FLOAT | 4779 | 6912 |
| 160 | GL_RG8 | GL_UNSIGNED_BYTE | 11772 | 10298 |
| 161 | GL_RG8_SNORM | GL_BYTE | 11771 | 10555 |
| 162 | GL_RG16F | GL_HALF_FLOAT | 6900 | 9324 |
| 163 | GL_RG32F | GL_FLOAT | 6601 | 7928 |
| 164 | GL_RG16F | GL_FLOAT | 6461 | 7965 |
| 165 | GL_R8 | GL_UNSIGNED_BYTE | 12249 | 10936 |
| 166 | GL_R8_SNORM | GL_BYTE | 12423 | 11080 |
| 167 | GL_R16F | GL_HALF_FLOAT | 8790 | 10254 |
| 168 | GL_R16F | GL_FLOAT | 15005 | 7751 |
| 169 | GL_RGBA | GL_UNSIGNED_BYTE | 11094 | 8086 |
| 170 | GL_RGBA | GL_UNSIGNED_SHORT_4_4_4_4 | 506 | 9767 |
| 171 | GL_RGBA | GL_UNSIGNED_SHORT_5_5_5_1 | 494 | 9790 |
| 172 | GL_RGB | GL_UNSIGNED_BYTE | 497 | 9689 |
| 173 | GL_RGB | GL_UNSIGNED_SHORT_5_6_5 | 532 | 9917 |
| 174 | GL_LUMINANCE_ALPHA | GL_UNSIGNED_BYTE | 487 | 10353 |
| 175 | GL_LUMINANCE | GL_UNSIGNED_BYTE | 12297 | 10944 |
| 176 | GL_ALPHA | GL_UNSIGNED_BYTE | 12310 | 10940 |
256x256 is the point at which the difference starts to become even more pronounced. The cases where the compute implementation is definitively worse are few and far between, and many of the cases in which it was previously worse are now neck and neck.
| # | Format | Type | calls/s current | calls/s compute |
|---|---|---|---|---|
| 177 | GL_R32F | GL_FLOAT | 3739 | 3348 |
| 178 | GL_RGBA8 | GL_UNSIGNED_BYTE | 4533 | 3409 |
| 179 | GL_RGB5_A1 | GL_UNSIGNED_BYTE | 4327 | 3354 |
| 180 | GL_RGBA4 | GL_UNSIGNED_BYTE | 4609 | 3274 |
| 181 | GL_SRGB8_ALPHA8 | GL_UNSIGNED_BYTE | 4520 | 3333 |
| 182 | GL_RGBA8_SNORM | GL_BYTE | 4296 | 3437 |
| 183 | GL_RGBA4 | GL_UNSIGNED_SHORT_4_4_4_4 | 236 | 3614 |
| 184 | GL_RGB5_A1 | GL_UNSIGNED_SHORT_5_5_5_1 | 237 | 3512 |
| 185 | GL_RGB10_A2 | GL_UNSIGNED_INT_2_10_10_10_REV | 235 | 2715 |
| 186 | GL_RGB5_A1 | GL_UNSIGNED_INT_2_10_10_10_REV | 230 | 3331 |
| 187 | GL_RGBA16F | GL_HALF_FLOAT | 1291 | 2694 |
| 188 | GL_RGBA32F | GL_FLOAT | 1127 | 1020 |
| 189 | GL_RGBA16F | GL_FLOAT | 1127 | 1000 |
| 190 | GL_RGB8 | GL_UNSIGNED_BYTE | 223 | 3648 |
| 191 | GL_RGB565 | GL_UNSIGNED_BYTE | 225 | 3550 |
| 192 | GL_SRGB8 | GL_UNSIGNED_BYTE | 227 | 3487 |
| 193 | GL_RGB8_SNORM | GL_BYTE | 358 | 3586 |
| 194 | GL_RGB565 | GL_UNSIGNED_SHORT_5_6_5 | 252 | 3567 |
| 195 | GL_R11F_G11F_B10F | GL_UNSIGNED_INT_10F_11F_11F_REV | 661 | 3084 |
| 196 | GL_R11F_G11F_B10F | GL_HALF_FLOAT | 1509 | 3055 |
| 197 | GL_R11F_G11F_B10F | GL_FLOAT | 1164 | 1222 |
| 198 | GL_RGB9_E5 | GL_UNSIGNED_INT_5_9_9_9_REV | 209 | 2636 |
| 199 | GL_RGB9_E5 | GL_HALF_FLOAT | 1499 | 2571 |
| 200 | GL_RGB9_E5 | GL_FLOAT | 1182 | 1234 |
| 201 | GL_RGB16F | GL_HALF_FLOAT | 1510 | 2955 |
| 202 | GL_RGB32F | GL_FLOAT | 1179 | 1112 |
| 203 | GL_RGB16F | GL_FLOAT | 1172 | 1247 |
| 204 | GL_RG8 | GL_UNSIGNED_BYTE | 5019 | 3572 |
| 205 | GL_RG8_SNORM | GL_BYTE | 5043 | 4201 |
| 206 | GL_RG16F | GL_HALF_FLOAT | 1796 | 3471 |
| 207 | GL_RG32F | GL_FLOAT | 1677 | 2701 |
| 208 | GL_RG16F | GL_FLOAT | 1668 | 2638 |
| 209 | GL_R8 | GL_UNSIGNED_BYTE | 5374 | 4084 |
| 210 | GL_R8_SNORM | GL_BYTE | 5409 | 2985 |
| 211 | GL_R16F | GL_HALF_FLOAT | 2222 | 880 |
| 212 | GL_R16F | GL_FLOAT | 3689 | 2904 |
| 213 | GL_RGBA | GL_UNSIGNED_BYTE | 4490 | 3179 |
| 214 | GL_RGBA | GL_UNSIGNED_SHORT_4_4_4_4 | 220 | 3366 |
| 215 | GL_RGBA | GL_UNSIGNED_SHORT_5_5_5_1 | 237 | 3405 |
| 216 | GL_RGB | GL_UNSIGNED_BYTE | 228 | 3392 |
| 217 | GL_RGB | GL_UNSIGNED_SHORT_5_6_5 | 253 | 3180 |
| 218 | GL_LUMINANCE_ALPHA | GL_UNSIGNED_BYTE | 229 | 3763 |
| 219 | GL_LUMINANCE | GL_UNSIGNED_BYTE | 5400 | 4099 |
| 220 | GL_ALPHA | GL_UNSIGNED_BYTE | 5473 | 3543 |
512x512 is even better for the compute-based implementation, which remains extremely consistent across nearly all cases. It now exhibits a commanding lead of almost 1500% for some cases, while at worst, it maintains a consistent rate and achieves only 60% of baseline performance for a few cases.
| # | Format | Type | calls/s current | calls/s compute |
|---|---|---|---|---|
| 221 | GL_R32F | GL_FLOAT | 831 | 711 |
| 222 | GL_RGBA8 | GL_UNSIGNED_BYTE | 839 | 724 |
| 223 | GL_RGB5_A1 | GL_UNSIGNED_BYTE | 856 | 707 |
| 224 | GL_RGBA4 | GL_UNSIGNED_BYTE | 831 | 644 |
| 225 | GL_SRGB8_ALPHA8 | GL_UNSIGNED_BYTE | 869 | 679 |
| 226 | GL_RGBA8_SNORM | GL_BYTE | 827 | 730 |
| 227 | GL_RGBA4 | GL_UNSIGNED_SHORT_4_4_4_4 | 77 | 709 |
| 228 | GL_RGB5_A1 | GL_UNSIGNED_SHORT_5_5_5_1 | 77 | 718 |
| 229 | GL_RGB10_A2 | GL_UNSIGNED_INT_2_10_10_10_REV | 75 | 664 |
| 230 | GL_RGB5_A1 | GL_UNSIGNED_INT_2_10_10_10_REV | 75 | 662 |
| 231 | GL_RGBA16F | GL_HALF_FLOAT | 304 | 550 |
| 232 | GL_RGBA32F | GL_FLOAT | 253 | 403 |
| 233 | GL_RGBA16F | GL_FLOAT | 253 | 358 |
| 234 | GL_RGB8 | GL_UNSIGNED_BYTE | 74 | 522 |
| 235 | GL_RGB565 | GL_UNSIGNED_BYTE | 74 | 594 |
| 236 | GL_SRGB8 | GL_UNSIGNED_BYTE | 74 | 618 |
| 237 | GL_RGB8_SNORM | GL_BYTE | 156 | 575 |
| 238 | GL_RGB565 | GL_UNSIGNED_SHORT_5_6_5 | 80 | 593 |
| 239 | GL_R11F_G11F_B10F | GL_UNSIGNED_INT_10F_11F_11F_REV | 160 | 585 |
| 240 | GL_R11F_G11F_B10F | GL_HALF_FLOAT | 353 | 489 |
| 241 | GL_R11F_G11F_B10F | GL_FLOAT | 282 | 366 |
| 242 | GL_RGB9_E5 | GL_UNSIGNED_INT_5_9_9_9_REV | 67 | 518 |
| 243 | GL_RGB9_E5 | GL_HALF_FLOAT | 352 | 488 |
| 244 | GL_RGB9_E5 | GL_FLOAT | 279 | 365 |
| 245 | GL_RGB16F | GL_HALF_FLOAT | 356 | 472 |
| 246 | GL_RGB32F | GL_FLOAT | 282 | 352 |
| 247 | GL_RGB16F | GL_FLOAT | 269 | 322 |
| 248 | GL_RG8 | GL_UNSIGNED_BYTE | 936 | 273 |
| 249 | GL_RG8_SNORM | GL_BYTE | 954 | 354 |
| 250 | GL_RG16F | GL_HALF_FLOAT | 434 | 494 |
| 251 | GL_RG32F | GL_FLOAT | 393 | 384 |
| 252 | GL_RG16F | GL_FLOAT | 392 | 284 |
| 253 | GL_R8 | GL_UNSIGNED_BYTE | 1398 | 624 |
| 254 | GL_R8_SNORM | GL_BYTE | 1415 | 630 |
| 255 | GL_R16F | GL_HALF_FLOAT | 535 | 530 |
| 256 | GL_R16F | GL_FLOAT | 819 | 490 |
| 257 | GL_RGBA | GL_UNSIGNED_BYTE | 861 | 504 |
| 258 | GL_RGBA | GL_UNSIGNED_SHORT_4_4_4_4 | 76 | 540 |
| 259 | GL_RGBA | GL_UNSIGNED_SHORT_5_5_5_1 | 78 | 685 |
| 260 | GL_RGB | GL_UNSIGNED_BYTE | 74 | 676 |
| 261 | GL_RGB | GL_UNSIGNED_SHORT_5_6_5 | 82 | 706 |
| 262 | GL_LUMINANCE_ALPHA | GL_UNSIGNED_BYTE | 75 | 825 |
| 263 | GL_LUMINANCE | GL_UNSIGNED_BYTE | 1431 | 997 |
| 264 | GL_ALPHA | GL_UNSIGNED_BYTE | 1399 | 962 |
1024x1024 is the true gauntlet for PBO downloads, and it’s really not something that is likely to be seen in many places. But pbobench covers it because why not, so here we are. The results here are much less pronounced just because the amount of time spent in memcpy on the CPU ends up being so large for both implmentations that the GPU doesn’t get much time to do work.
Improvements are ongoing for compute-accelerated PBOs, and performance continues to rise. I’m looking forward to tackling uploads next, as that should directly improve load times for GL-based games across the board.
Also, Graphics.
As part of the ongoing saga of working for a company that has an interest in gaming, games have been played recently.
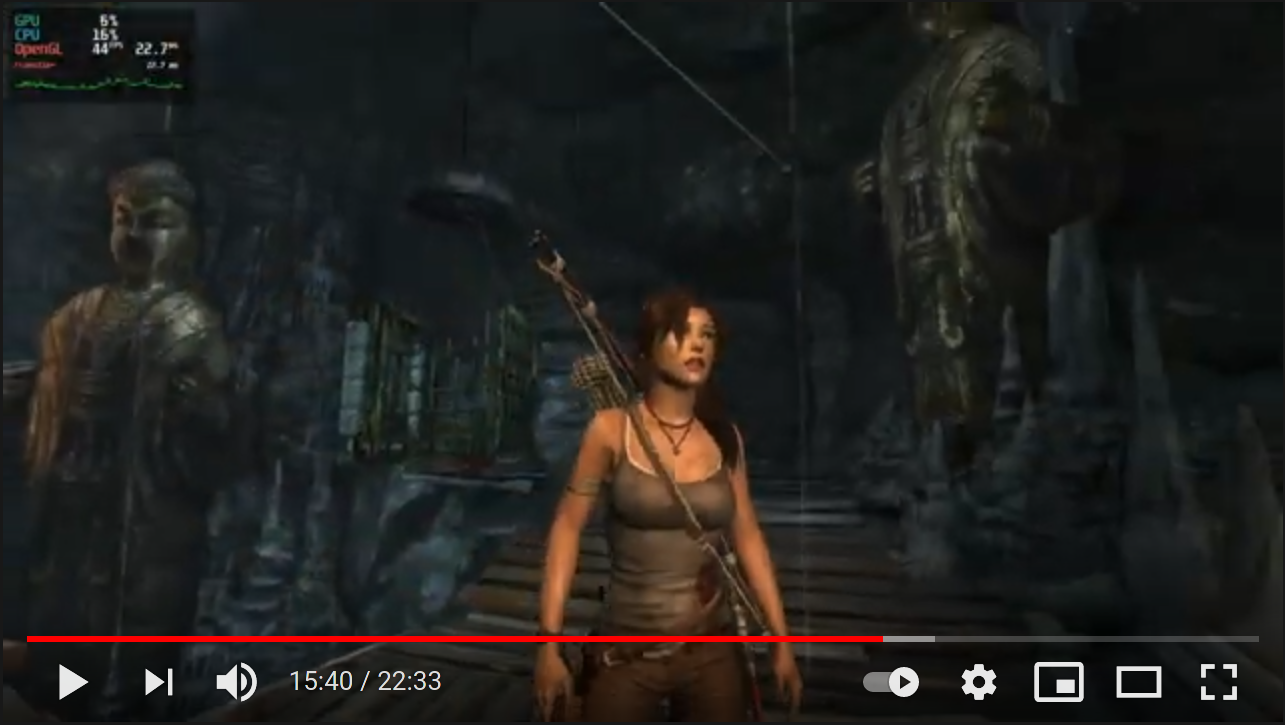
One of those games is Tomb Raider (2013), and until very recently it had some issues when run on zink:

Here we see the wild triangle in its native habitat, foraging for sustenance among its siblings.
All of that changed today, however, when I rebased zink-wip from a couple weeks ago and then hucked it back into the repo with a new snapshot name and zero testing.
I was subsequently informed that I had broken our beautiful triangle princess, and Senior Misrendering Connoisseur Witold Baryluk has provided us with actual gameplay footage with all settings set to EXTREME: