Architecture
It’s Time.
I’ve been busy cramming more code than ever into the repo this week in order to finish up my final project for a while by Friday. I’ll talk more about that tomorrow though. Today I’ve got two things for all of you.
First, A Riddle
Of these two screenshots, one is zink+ANV and one is IRIS. Which is which?
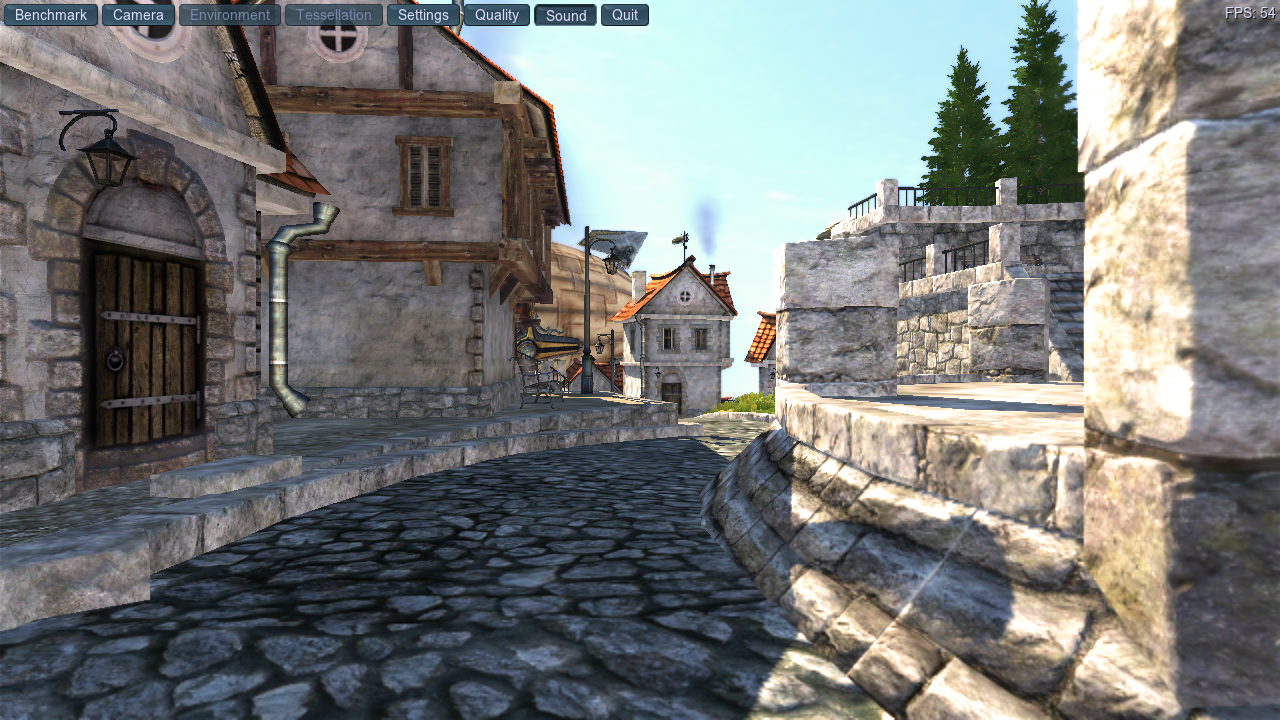
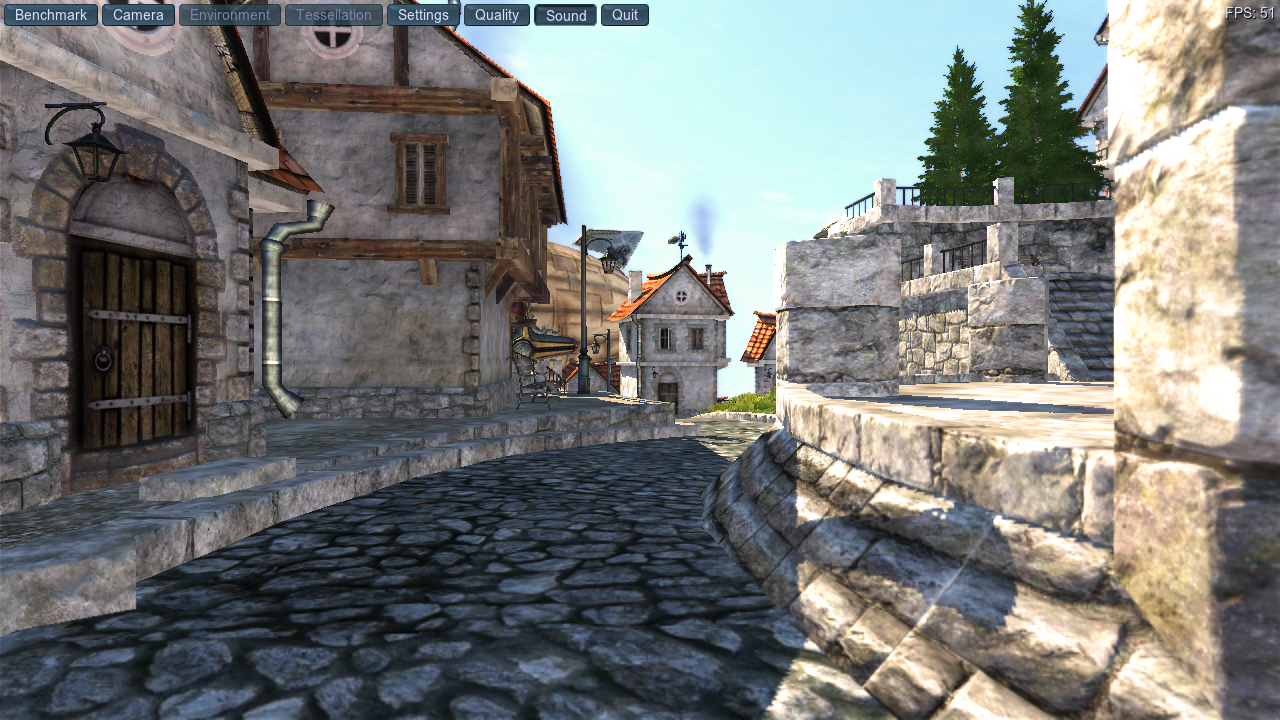
Second, Queue Architecture
Let’s talk a bit at a high level about how zink uses (non-compute) command buffers.
Currently in the repo zink works like this:
- there is 1 queue
- there are 4 command buffers used in a ring
- after every flush (e.g.,
glFlush), the command buffers cycle - the driver flushes itself internally on pretty much every function call
- any time an in-use command buffer is iterated to, the driver stalls until the command buffer has completed
In short, there’s a huge bottleneck around the flushing mechanism, and then there’s a lesser-reached bottleneck for cases where an application flushes repeatedly before a command buffer’s ops are completed.
Some time ago I talked about some modifications I’d done to the above architecture, and then things looked more like this:
- there is 1 queue
- there are 4 command buffers used in a ring
- after every flush (e.g.,
glFlush), the command buffers cycle* after - the driver defers all possible flushes to try and match 1 flush to 1 frame
- any time an in-use command buffer is iterated to, the driver stalls until the command buffer has completed
The major difference after this work was that the flushing was reduced, which then greatly reduced the impact of that bottleneck that exists when all the command buffers are submitted and the driver wants to continue recording commands.
A lot of speculation has occurred among the developers over “how many” command buffers should be used, and there’s been some talk of profiling this, but for various reasons I’ll get into tomorrow, I opted to sidestep the question entirely in favor of a more dynamic solution: monotonically-identified command buffers.
Monotony
The basic idea behind this strategy, which is used by a number of other drivers in the tree, is that there’s no need to keep a “ring” of command buffers to cycle through, as the driver can just continually allocate new command buffers on-the-fly and submit them as needed, reusing them once they’ve naturally completed instead of forcibly stalling on them. Here’s a visual comparison:
The current design:
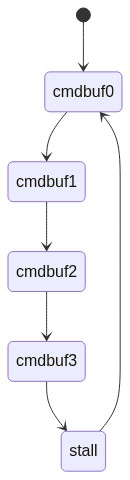
Here’s the new version:
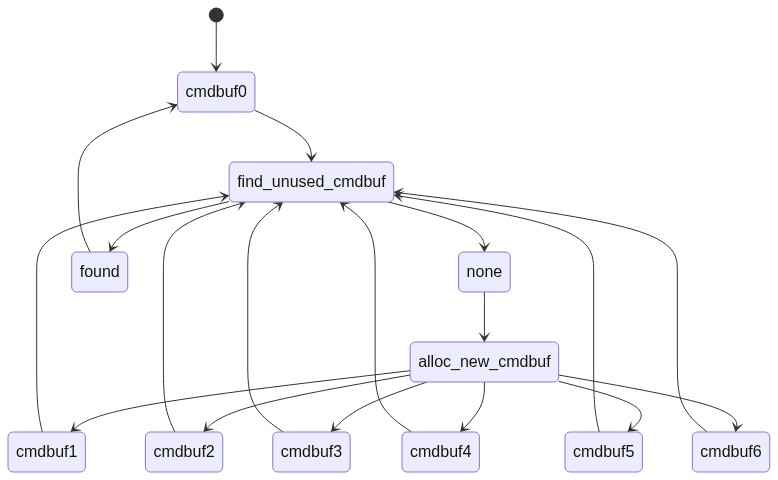
This way, there’s no possibility of stalling based on application flushes (or the rare driver-internal flush which does still exist in a couple places).
The architectural change here had two great benefits:
- for systems that aren’t CPU bound, more command buffers will automatically be created and used, yielding immediate performance gains (~5% on Dave Airlie’s AMD setup)
- the driver internals get massively simplified
The latter of these is due to the way that the queue in zink is split between gfx and compute command buffers; with the hardcoded batch system, the compute queue had its own command buffer while the gfx queue had four, but they all had unique IDs which were tracked using bitfields all over the place, not to mention it was frustrating never being able to just “know” which command buffer was currently being recorded to for a given command without indexing the array.
Now it’s easy to know which command buffer is currently being recorded to, as it’ll always be the one associated with the queue (gfx or compute) for the given operation.
This had further implications, however, and I’d done this to pave the way for a bigger project, one that I’ve spent the past few days on. Check back tomorrow for that and more.